Índices cluster
¿Qué es y para qué sirve un índice cluster o agrupado?
En SQL Server existe, además de los índices que todos conocemos, un tipo especial que se llaman índices cluster, clustered index o índices agrupados; todos los anteriores son sinónimos para un índice que tienen la característica de que son índices únicos en una tabla que ordenan físicamente los registros de la tabla en base a ese índice; es decir, los datos -sin necesidad de dar un ORDER BY en una instrucción SELECT- ya están ordenados, siempre están ordenados. Esto representa diversas ventajas importantes
- Cuando se ejecuta una instrucción SELECT sin un ORDER BY, los registros pueden regresarse en un orden impredecible, y esto puede dar lugar a comportamientos erraticos en las aplicaciones. Al tener un índice cluster los registros, a menos que se indique otra cosas, se regresarán siempre en base al orden del índice.
- Cuando se hacen consultas que involucren una cláusula BETWEEN utilizando el campo por el que se forma el índice cluster son muy eficientes ya que el motor de bases de datos solo necesita encontar el primer registro (el límite inferior del rango especificado en el BETWEEN) y a partir de ahí leera secuencialmente los registros (porque físicamente están ordenados en base al campo índice) hasta que ya no se cumpla el rango establecido.
- Las lecturas son más eficientes, ya que es el único índice que se guarda no como una estructura adicional, sino que el índice es la tabla. Esta forma de operar es muy característica de los índices cluster, que debe ser detallada.
¿Cómo trabaja o cómo está organizado un índice cluster?
Los índices tradicionales
Todos los demás índices conocidos son una estructura adicional a los datos, es decir, por un lado están los registros, y por otro lado está esa estructura llamada índice -que para efectos prácticos representaremos como un árbol- con la llave del índice ordenada. Esto provoca que si se quiere hacer una búsqueda u ordenamiento en base a esa llave el motor de base de datos tiene que leer el árbol buscando el registro requerido (donde se guarda únicamente la llave y la posición física donde se encuentra el registro completo) y luego se hace el salto (lookup en el plan de ejecución) para leer el registro propiamente dicho.
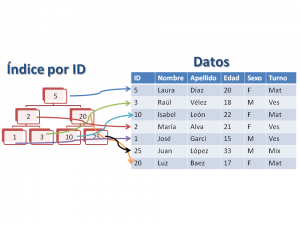 Esta imagen ejemplifica un índice por ID, donde la estructura del índice está en un árbol separado (el de la izquierda) que es donde se realizan las búsquedas, y cuando se encuentra la llave requerida, entonces de hace el «salto» (lookup en el plan de ejecución) para extraer la totalidad del registro.
Esta imagen ejemplifica un índice por ID, donde la estructura del índice está en un árbol separado (el de la izquierda) que es donde se realizan las búsquedas, y cuando se encuentra la llave requerida, entonces de hace el «salto» (lookup en el plan de ejecución) para extraer la totalidad del registro.
Los índices cluster o agrupados
Por su lado, un índice agrupado o cluster organiza los registros -datos- y el índice en la misma estructura, de tal manera que se arma un árbol ordenado en base a la llave -como en los demás índices- pero en cada nodo se guarda el registro completo, de tal manera que no hay que hacer el lookup de los demás índices. Esto, que pareciera un costo mínimo, provoca que el disco duro haga menos lecturas o saltos y siempre será mejor. La siguiente imagen ejemplifica el mismo índice de la imagen anterior (por ID) pero ahora siendo un índice cluster.

En este índice, como queda de manifiesto en la imagen, el índice y los datos son una misma estructura y cuando se realiza una búsqueda por ID no es necesario hacer el salto adicional como en los demás índices.
Características de los índices agrupados o cluster
Por la característica de los índices cluster en SQL Server, es necesario tener ciertas consideraciones importantes:
- Un índice cluster debería ser único
- De preferencia, la llave en un índice cluster debe ser pequeña incremental y no debería ser modificada.
Los índices cluster o agrupados deben ser únicos
Esto se refiere a dos tipos de unicidad:
- Por un lado la llave debe ser única (para evitar el trabajo adicional de trabajar con duplicados) por lo que es muy común que se utilice para la llave principal (que ya es única por naturaleza) o por lo menos con alguna llave secundaria (aunque es muy raro ver esta segunda opción en la vida real). Si bien no es obligatorio que sea así, si se trata de lo más común.
- Adicional a la llave única, el índice cluster en una tabla es único; es decir, no pueden existir dos o más índices cluster por tabla. Y esto tiene sentido si recordamos que los datos y el índice cluster se guardan en la misma estructura, son lo mismo.
La llave debe ser pequeña
Esta es una característica que comparte con todos los demás índices, y como regularmente el índice cluster es el índice de la llave primaria, debe ser pequeña para ahorrar espacio (que además de espacio, ahorra tiempo de lectura y ancho de banda de transmisión). Como en el caso de la llave única, esto no es obligatorio, pero si es lo más común.
La llave debe ser incremental
Cuando se añade un registro debe ser añadido al índice (por que, recordemos, que índice cluster y tabla son lo mismo) es más fácil añadirlo al final (como una nueva hoja en el árbol) que a la mitad del árbol y «recorrer» todos los registros que «desplaza», se estila que la llave de un índice cluster sea un campo autonumérico o incremental. Como siempre, no es obligatorio, pero es lo que casi siempre se ve.
Esto lleva a una característica común en casi todas las llaves de un índice cluster, y es que regularmente son llaves artificiales, para que puedan ser incrementales o autonuméricas.
La llave no debe ser modificada
Una consecuencia del punto anterior (que sea incrememental para evitar sobre carga de trabajo al añadir llaves intermedias) es que no sea modificada, ya que si se cambia una llave en particular a un valor que tenga que insertarse en un lugar intermedio del índice se provocaría una carga adicional de trabajo para insertar el registro en su nueva posición y, sobre todo, en «recorrer» los registros que sean necesarios. Obviamente, se puede cambiar el valor de la llave del índice cluster, pero el costo añadido en la actualización no justifica el posible beneficio de poder cambiar la llave.
Disclaimer:
Si bien las llaves pueden no ser únicas, se pueden modificar o incluso pueden no ser incrementales, es lo más recomendable en términos de performance de las consultas